





Tu plataforma de anotación IA, alojada en Francia
El kit de anotación para visión por ordenador impulsado por CVAT, instalado y mantenido por DINAO. Tus imágenes, vídeos y datasets permanecen en nuestros servidores franceses — la anotación asistida por IA, en una infraestructura soberana.
¿Qué es CVAT?
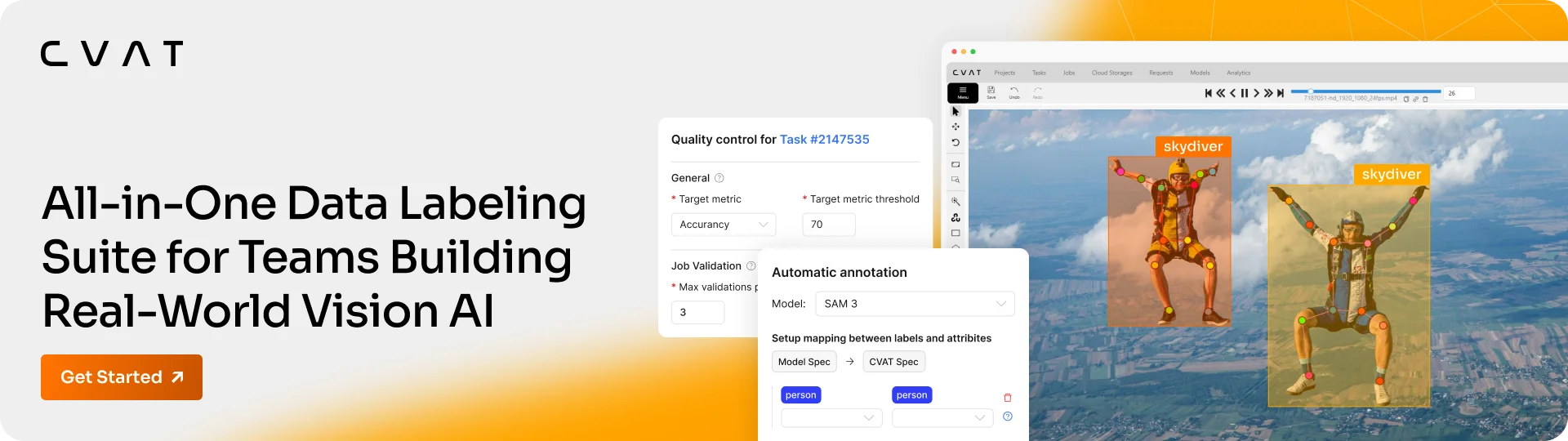
CVAT (Computer Vision Annotation Tool) es una plataforma web de código abierto para la anotación de imágenes, vídeos y nubes de puntos 3D, diseñada para producir los datasets de entrenamiento de la visión por ordenador. Cubre todos los tipos de anotación — cajas delimitadoras, polígonos, polilíneas, máscaras de segmentación, puntos clave/esqueletos, cuboides, elipses, etiquetas — y gestiona el seguimiento y la interpolación en vídeo.
Pensada para equipos, CVAT aporta la gestión de proyectos y tareas, el control de calidad (ground-truth, matriz de confusión), el análisis de datos, la gestión de roles (RBAC), así como la anotación asistida por IA mediante modelos como SAM/SAM 2, YOLO o Mask R-CNN. La exportación cubre más de 20 formatos estándar (COCO, YOLO, Pascal VOC…).
A nivel técnico, CVAT se basa en Django y React, con PostgreSQL y Redis, desplegado en una stack Docker multi-contenedor. La autoanotación se apoya en Nuclio en serverless, y se recomienda una GPU NVIDIA para los modelos más pesados. Una API REST, un SDK Python y una CLI completan el conjunto.
Aloja CVAT en DINAO
Niveles de recursos compatibles con los requisitos de CVAT (mínimo 2 vCPU / 4 Go / 20 Go). Alojado en Francia, gestionado.
Esta aplicación utiliza una imagen no oficial / no verificada o requiere recursos a medida. La estudiamos y desplegamos bajo presupuesto.
Solicitar presupuestoEsta aplicación utiliza IA
El contenedor aloja la aplicación, no el motor de IA (que exige GPUs dedicadas) : la inferencia se conecta externamente, con tu propia clave de proveedor. Prioriza un motor soberano — Mistral AI, NumSpot, Scaleway o OVHcloud AI Endpoints (Francia, GDPR) ; un actor internacional (OpenAI, Anthropic…) solo si una capacidad específica lo exige. Suscripciones de inferencia no incluidas en el alojamiento.
Detalles técnicos
Te preguntas…
¿Para qué sirve CVAT?
CVAT es un kit de anotación para visión por ordenador. Se anotan imágenes, vídeos y nubes de puntos 3D para producir los datasets de entrenamiento necesarios para los modelos de IA de detección, segmentación o clasificación.
¿La anotación asistida por IA se ejecuta en tu infraestructura o en un cloud externo?
En la edición autoalojada, los modelos de autoanotación (SAM, YOLO…) se ejecutan localmente en tu instancia DINAO, sin llamadas a servicios cloud externos. Tus imágenes no salen del servidor — véase la nota de soberanía más abajo.
¿Qué formatos de exportación se admiten?
Más de 20 formatos estándar: COCO, YOLO, Pascal VOC y muchos otros. Recuperas tus datasets en el formato esperado por tu framework de entrenamiento, a través de la interfaz, la API o el SDK Python.
¿Hace falta una GPU?
La anotación manual funciona sin GPU. Para la autoanotación con modelos grandes (SAM en particular), se recomienda encarecidamente una GPU NVIDIA: está disponible como opción (fórmula Equipo IA) o dedicada (fórmula Producción).
¿Puedo cambiar de fórmula o exportar mis datos?
Sí. Subes o bajas de nivel en cualquier momento, y tus datasets siguen siendo exportables en formatos estándar: no hay bloqueo propietario.
